 Les
mťmoires associatives
Les
mťmoires associatives - Architecture
du rťseau
- Le
principe
- L'algorithme
![]() Modification
de la structure du rťseau
Modification
de la structure du rťseau
![]() Mise
en place d'une couche de sortie rťcurrente
Mise
en place d'une couche de sortie rťcurrente
![]() Mise
en place d'une couche de sortie non-rťcurrente
Mise
en place d'une couche de sortie non-rťcurrente
Modification de la structure du rťseau
![]() Modification
de la structure du rťseau
Modification
de la structure du rťseau
![]() Mise
en place d'une couche de sortie rťcurrente
Mise
en place d'une couche de sortie rťcurrente
![]() Mise
en place d'une couche de sortie non-rťcurrente
Mise
en place d'une couche de sortie non-rťcurrente
Líalgorithme díHopfield essaye de se rapprocher díun exemple appris. Pour notre part, on souhaiterait donner une entrťe ŗ líalgorithme et rťcupťrer uniquement une sortie qui nía pas obligatoirement la mÍme taille que líentrťe. On est donc obligť de modifier sensiblement líalgorithme afin de donner une entrťe de taille n retournant une sortie de taille m.
On peut aussi essayer de changer quelques rŤgles relatives ŗ la structure du rťseau au risque de perdre les critŤres de convergence.
Hormis les paramŤtres de dťsapprentissage, deux autres paramŤtres importants peuvent subir des modifications :
![]() L'auto-activation
du neurone
L'auto-activation
du neurone
Le modŤle de base du rťseau de Hopfield est le modŤle de Ising. Les atomes tentent de prendre la polaritť du champ ambiant. Cette polaritť ne concerne que les liaisons entre les atomes. En tenant compte de líauto-activation du neurone, on prend en considťration de faÁon forte la polaritť du systŤme. En effet du fait de la rŤgle díapprentissage, les neurones auront une auto-activation maximale (correspondante au nombre díexemples).La moyenne de ces activations donnera donc la polaritť ambiante au niveau de tout le rťseau. Les modifications locales interviendront gr‚ce aux poids sur les connexions (interactions). Le critŤre de convergence níest plus vťrifiť avec cette hypothŤse. Malgrť tout, les tests ont permis de monter une convergence dans la majoritť des cas.
![]() Modification
des poids Synchrone ou Asynchrone ?
Modification
des poids Synchrone ou Asynchrone ?
Le rťseau de base prťconise une modification des activations de maniŤre asynchrone. Pourquoi ne pas donc considťrer une modification des activations soudaine de faÁon synchrone. Cíest ŗ dire quíŗ ce niveau líactivation des neurones ne dťpend que de líťtat prťcťdent et plus de líťtat en cours, contrairement ŗ la modification asynchrone qui dťpend ŗ la fois de líťtat courant et prťcťdent.
Lŗ aussi, le caractŤre asynchrone du rťseau ne satisfait plus les critŤres de convergence sŻre. Cependant on arrive ŗ converger la grande majoritť des cas (quasiment toujours). Le problŤme semble apparaÓtre dťs que líon associe le caractŤre synchrone avec la non auto-activation du neurone. En effet ce mode converge trŤs rarement, mais cíest le seul. Le but de ces modifications de mode de fonctionnement est bien sŻr díessayer díamťliorer le taux díerreur en gťnťralisation (sur apprentissage).
L'architecture du rťseau n'est pas fondamentalement modifiťe. La diffťrence intervient au niveau de la phase de gťnťralisation.
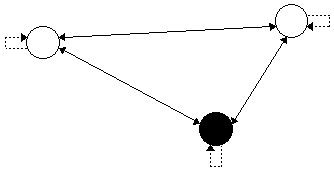
Architecture du rťseau (en noir une sortie)
La phase díapprentissage est strictement la mÍme. Par contre, la gťnťralisation est un peu modifiťe. Au cours de la phase de gťnťralisation par dťfinition, on ne connaÓt pas la sortie. On initialise donc les entrťes puis on calcule les sorties en fonction des entrťes. La rťcurrence peut donc Ítre lancťe maintenant.
![]() Algorithme
Algorithme
Líarchitecture subit ici des modifications importantes dans le sens ou les sorties ne sont plus rťcurrentes et níont plus de relations entre elles.
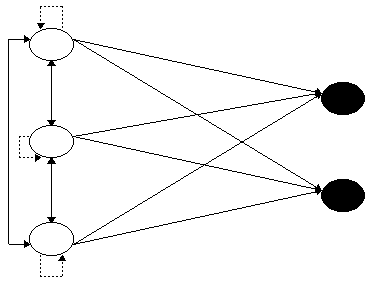
En noir les neurones de sortie (non-recurrents)
Au cours le la phase díapprentissage, les connexions venant des neurones díentrťes vers les autres neurones sont modifiťs. Par contre, les neurones de sortie níont aucune connexion allant vers un autre neurone. On isole ainsi la zone díentrťe et de sortie. Le principal changement apparaÓt dans le calcul des entrťes ŗ un neurone de la couche de sortie.
![]() Algorithme
Algorithme
On calcule les sorties puis on ne garde activťe que la sortie dont líentrťe totale est la plus grande et supťrieure ŗ 0. On peut donc se retrouver dans le cas je ne sais pas ou aucun des neurones nía pu Ítre activť. La raison de cette sortie compťtitive rťside dans la structure des classes de sortie. En effet elles sont contradictoires. Cíest ŗ dire que líon ne peut pas avoir la sortie 1 activť avec la sortie 3.(Par exemple vote dťmocrate et rťpublicain est incompatible)Une sortie est donc activťe ŗ la fois. Les autres restent ŗ líťtat 0 (ou -1).
L'algorithme est identique au cas prťcťdent et peut mÍme Ítre appliquť ŗ un ensemble de sorties rťcurrentes.
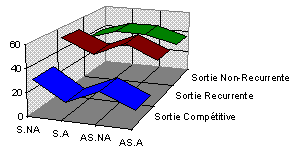
Variation de l'erreur sur la base Lenses en fonction de l'architecture
On remarque bien líintťrÍt díun tel dťcoupage des sorties sous une forme compťtitive. Les rťsultats sont considťrťs avec un dťsapprentissage de -0.01 de force en une seule passe.
La premiŤre solution proposťe pour augmenter les rťsultats est bien sŻr de rťaliser une troncature prťalable des bases. On ťlimine alors les cas qui crťent des oublis dans le rťseau. (Exemple du 8 et du 9 en reconnaissance). Les rťsultats s'amťliorent trŤs fortement gr‚ce ŗ un, dťcoupage judicieux des donnťes ŗ faire apprendre au rťseau.
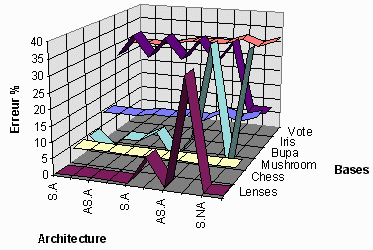
Rťsultats sur base tronquťe en rťseau ŗ compťtition
Vote en base complŤte donne une erreur lťgŤrement infťrieure. Il est donc important d'effectuer un trŤs bon dťcoupage des bases avant l'apprentissage.
Le paramŤtre A (Charge du rťseau) est souvent trŤs grand, du moins nettement supťrieur ŗ 0.14. Díou líidťe de coder diffťremment la base. On peut par exemple dans un premier temps coder un 1 par 1 1 1 1 1 et un 0 par 0 0 0 0 0. Ainsi, on augmente le nombre de neurones et on diminue par la mÍme occasion le paramŤtre A. Les rťsultats sont identiques que prťcťdemment. Cela peut sĎexplique par le fait que ce changement multiplie par x la force díune classe quelconque. Les entrťes totales au niveau des sorties sont donc toujours identiques ŗ un facteur multiplicatif x prťs.
Díou líidťe de coder de faÁon alťatoire les entrťes. Cíest ŗ dire que líon prend une entrťe et líon ťtend la valeur boolťenne 1 par 1 0 1 0 par exemple (alťatoire) et donc 0 par 1 0 1 0 (le complťmentaire). De cette faÁon, on ťlimine le problŤme prťcťdent. Cependant, les rťsultats restent les mÍmes dans le cas díun rťseau de Hopfield ŗ sorties compťtitives.