 Les
mémoires auto-associatives
Les
mémoires auto-associatives - Architecture
du réseau
- Le
principe
- L'algorithme
- Modification
de la structure
- Mise
en place d'une couche de sortie récurrente
- Mise
en place d'une couche de sortie non-récurrente
- Mise
en place de sorties compétitives
- Extension
des bases
Voici dans un premier temps des tests sur le programme dans sa forme originelle, c'est à dire avec des entrées équivalentes aux sorties. Le but de cet exemple est de montrer une utilisation d'un réseau de Hopfield dans le cadre d'une reconnaissance de caractères.
On donne au réseau la base suivante à apprendre (matrice de 5x9 pixels).
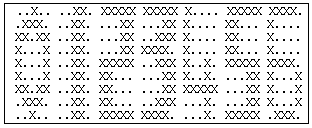
On présente alors un 0 un peu bruité en entrée du réseau. Voici les étapes successives sans la restitution de l'image initiale:
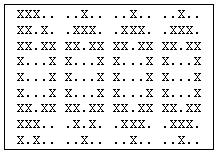
La convergence semble parfaite dans le cadre d'une petite base de données et sur un exemple faiblement bruité.
Une étude sur plusieurs exemples à monter l’existence d’une zone à partir de laquelle on assiste à une plus mauvaise convergence du réseau vers des motifs indésirables. Cette zone semble se situer entre 0.13 et 0.15 (Charge du réseau) comme le préconiser Hopfield. Malgré tout, cette détection est très liée aux exemples utilisés mais aussi au motif dégradé que l’on tente de retrouver.
Considérons une base d'apprentissage plus large pour la détection du même 0 avec le même bruitage que dans l'exemple précédent.

Dans cet exemple, on assiste à une convergence vers un état poubelle (A = 0.22). Cependant, on arrive encore à retrouver le motif du 0 (reconnaissable). Il peut arriver, si le motif est très bruité que la convergence s’opère vers un autre élément. On peut prendre l’exemple du motif 1 bruité à 40% qui restitue au bout de quelques itérations un motif poubelle ressemblant à un 3.
En diminuant le A(0.15) on arrive à un meilleur résultat. Il faut aussi préciser que les éléments 8 et 9 sont très perturbateurs même si avec un même rapport A(0.15) et les éléments 8 et 9 on obtient de mauvais résultats. On en déduit donc que certains éléments appris déstabilisent le réseau d'une façon très importante.
Néanmoins, l’utilisation d’une session de désapprentissage faible améliore sensiblement les résultats en éliminant des cas poubelle. On peut alors étendre, soit le pourcentage de bruitage, soit le rapport A (Charge du système). Malheureusement, il ne faut pas croire qu’un fort désapprentissage va résoudre tous les problèmes. Un fort désapprentissage (force de correction proche de 1), où trop d’itérations sur un désapprentissage (amenant une correction supérieure à 1) parasite aussi fortement le réseau. La meilleure solution a semblé être un désapprentissage de force -0.01 répété entre 1 et 10 fois. Ceci est bien valide, car notre nombre de neurones est important vis-à-vis des exemples et donc des cas possibles. La probabilité de tomber avec la génération aléatoire de cas sur un motif connu ou de s’en rapprocher est donc très faible. On ne risque pas de pénaliser un motif appris. Ce n’est malheureusement pas toujours le cas avec les bases de données (Iris, Lenses, Mushroom, Bupa, Vote et Chess) qui dans le pire des cas peuvent donner un rapport a de l’ordre de 100 . Le désapprentissage est souvent utile mais il faut bien vérifier ses conditions d’applicabilité.

Exemple de restitution avec un apprentissage sur 7 éléments et un signal de départ bruité à plus de 16%. Un désapprentissage léger est aussi appliqué au réseau ce qui nous permet ici de tendre vers un état connu, c'est à dire 1.