Ce rťseau a ťtť inventť par Hecht Nielsen. Il nía pas de caractťristique rťvolutionnaire nouvelle mais ressemble beaucoup plus ŗ un assemblage de piŤces venant d'autres rťseaux. Une approche de ce rťseau bien que limitťe est assez intťressante au titre díune introduction aux rťseaux ŗ compťtition du type Kohonen. Le grand intťrÍt de ce type de rťseau est d'effectuer des classifications et par extension de la reconnaissance.
Líalgorithme de contre-propagation utilise une architecture proche du perceptron. On a en effet une couche díentrťe, une couche de sortie mais aussi une et une seule couche intermťdiaire (bien que líon puisse concevoir ce rťseau avec plusieurs couches cachťes).

Líoriginalitť du rťseau vient du fait quíil mťlange deux types díapprentissage en fonction de la couche considťrťe.
Les rŤgles de calcul des entrťes ŗ un neurone sont identiques aux autres rťseaux. Cependant, la rŤgle díactivation díun neurone, et cíest la nouveautť est de type compťtitive. Cíest ŗ dire que líon va dťterminer un neurone gagnant qui lui seul sera activť.
En effet, de maniŤre interne, ce rťseau effectue une classification. Ceci peut Ítre intťressant pour la reconnaissance de formes. Il suffit de faire en sorte quíau cours de líapprentissage, on apprenne toutes les formes ŗ reconnaÓtre. Elles vont donc aller se nicher dans les neurones de cette couche. Il faut par consťquent prťvoir assez de neurones dans cette couche.
Pour bien fixer líutilitť de ce rťseau, considťrons líexemple suivant : A partir díune image díun missile, on veut connaÓtre son angle díinclinaison. On fixe alors en entrťe la matrice des pixels reprťsentant le missile. La couche de sortie pourra par exemple nous donner líangle. La couche intermťdiaire pourra alors servir ŗ reconnaÓtre des angles du type 0į, 45į, 90į, ... . On a donc autant de neurone dans cette couche que de catťgories ŗ classer.
![]() L'apprentissage
L'apprentissage
Líapprentissage síeffectue en mode supervisť. En díautres termes, on prťsente au rťseau des modŤles du type (entrťe, sortie). Les valeurs des poids des connexions de la couche intermťdiaire et de sortie sont choisis alťatoirement. On entraÓne en premier lieu la couche intermťdiaire en prťsentant les exemples. Pour chaque exemplaire, on effectue alors une normalisation de líentrťe pour ťviter une divergence du rťseau:
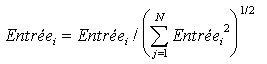
Pour chaque neurone intermťdiaire on calcule líactivation totale du neurone. On rťpŤte le processus pour chaque neurone avant de modifier les poids selon une rŤgle du type Widrow-Hoff. Cependant, on ne modifie pas le poids de toutes les connexions mais seulement les poids ę du neurone gagnant Ľ, cíest ŗ dire du neurone ŗ la plus forte activation :
Wgagnant,i = Wgagnant,i + Alpha (Entrťei - ti), t activation du neurone
Cette rŤgle va avoir pour effet de rapprocher encore plus le vecteur des poids du vecteur díentrťe correspondant.
Pour arrÍter cet apprentissage, on attend que
DŤs que la couche intermťdiaire est capable de placer un ťlťment dans une catťgorie, on peut procťder ŗ líapprentissage de la couche de sortie. On propage alors líentrťe vers la couche intermťdiaire afin díťlire le neurone vainqueur. On ajuste alors les connexions de ce neurone vers la sortie ŗ líaide de la rŤgle :
Wj,gagnant = Wj,gagnant + Beta (Sortiel-Wj,gagnant)
Cette phase se poursuit tant quíun critŤre de convergence níest pas atteint. Par exemple, on peut fixer comme critŤre, líerreur entre la pondťration et la sortie rťelle est infťrieure ŗ un seuil (0.01, ...).
![]() La phase
de gťnťralisation
La phase
de gťnťralisation
On effectue tout simplement une propagation de líentrťe vers la couche intermťdiaire afin díťlire un neurone gagnant. Ce neurone dťterminť, on propage alors vers la couche de sortie.
Voici díabord des rťsultats sur de la reconnaissance de forme. On apprend au rťseau ŗ reconnaÓtre 4 formes reprťsentant un missile en inclinaison. La sortie doit donc nous donner cette inclinaison. Par contre il est assez difficile de faire en sorte que le rťseau apprenne les bases de donnťes (Lenses, Mushroom, Vote, ...) car elles sont trop proches et bloquent la phase de convergence au niveau de la correction des poids. De plus, il faut sans doute faire en sorte quíil y ait une catťgorie par exemple. Cependant en diminuant la taille de la base on obtient des rťsultats.

Les donnťes ŗ apprendre

Le rťsultat en gťnťralisation sur apprentissage
Cette mťthode est relativement rapide. On peut peut-Ítre líutiliser pour la formation des propositions logiques.
Les paramŤtres utilisťs sont :
Il serait intťressant de traiter plus en dťtail ce rťseau car on peut ťviter les oscillations qui síopŤrent souvent avec nos bases (formes trop proches et trop de cas díapprentissage) en faisant une modulation des coefficients díapprentissage. Par exemple, on peut partir de coefficients trŤs gros puis les diminuer trŤs progressivement ou faire líinverse pour ťliminer des cas de la base. Ce rťseau est aussi extensible en propagation inverse, mais malheureusement, je níai pas pu trouver de littťrature traitant plus en dťtail de cet algorithme.