Les rťseaux mono-couche (couche díentrťe et/ou de sortie) peuvent Ítre entraÓnťs avec des rŤgles díapprentissage relativement simple. En contrepartie, ce genre de rťseau est limitť au calcul de fonctions trŤs simples. Díou líintťrÍt de crťer des rťseaux plus ťlaborťs, contenant par exemple des neurones cachťs, c'est ŗ dire des neurones qui ne sont ni de la couche d'entrťe ni de la couche de sortie. Cependant, mÍme si ces rťseaux ont des capacitťs de calcul plus grandes, leur apprentissage ou líattribution des poids des connexions devient trŤs difficile. Les rťseaux multil-couches comme par exemple le perceptron multicouche sont assez rťcents. Ce dernier utilise d'ailleurs líalgorithme de rťtro-propagation du gradient pour effectuer la mise en place de la pondťration du rťseau.
 L'architecture
du rťseau
L'architecture
du rťseauLe rťseau prťsentť ici prťsente les caractťristiques suivantes:
Rappelons les formules de calcul pour un neurone. Considťrons donc un neurone i de la couche intermťdiaire k + 1. Il reÁoit en entrťe une somme pondťrťe fonction de l'ťtat des neurones prťcťdents. On effectue donc:
Les calculs prťsentťs ci-dessus sont d'ordre gťnťral et peuvent s'appliquer ŗ un grand nombre de rťseaux.

Architecture de base du rťseau
Le principeLíalgorithme de rťtro-propagation du gradient est utilisť dans le perceptron multicouche. La phase importante ou ce dernier est utilisť est bien ťvidemment líapprentissage.
 L'apprentissage
L'apprentissageDans un cadre plus gťnťral, líapprentissage consiste en un entraÓnement du rťseau. On prťsente au rťseau des entrťes et on lui demande de modifier sa pondťration de telle sorte que líon retrouve la sortie correspondante. Líalgorithme consiste dans un premier temps ŗ propager vers líavant les entrťes jusqu'ŗ obtenir une entrťe calculťe par le rťseau. La seconde ťtape compare la sortie calculťe ŗ la sortie rťelle connue. On modifie alors les poids de telle sorte quíŗ la prochaine itťration, líerreur commise entre la sortie calculťe et connue soit minimisťe. Malgrť tout, il ne faut pas oublier que líon a des couches cachťes. On rťtro-propage alors líerreur commise vers líarriŤre jusqu'ŗ la couche díentrťe tout en modifiant la pondťration. On rťpŤte ce processus sur tous les exemples jusqu'ŗ temps que líon obtienne une erreur de sortie considťrťe comme nťgligeable.
 Un Exemple
Un Exemple
Afin de voir un petit peu mieux ce qui se passe considťrons un rťseau assez simple composť díune couche díentrťe, une seule couche intermťdiaire et une couche de sortie.
On commence tout díabord les calculs par une initialisation alťatoire des poids. Examinons alors la mťthode díajustement des poids sur un seul essai :
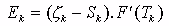
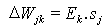
On re-ajuste les poids vers les neurones intermťdiaires.
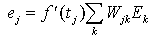
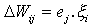
Les notations utilisťes sont les suivantes:

La gťnťralisationLíalgorithme de gťnťralisation est trŤs simple dans le sens ou il ne fait quíune propagation de líentrťe vers líavant. On ne calcule pas díerreur ťtant donnť díune part que la modification doit nous donner ę un bon rťsultat Ľ et d'autre part, que la vraie valeur de sortie n'est pas connue.
L'algorithmeExemple de structure
de donnťes
Le programme proposť est ťcrit en langage C. La structure utilisťe pour coder le rťseau est relativement intuitive :
Un neurone est donc une entitť comprenant le vecteur des poids vers les neurones de la couche suivante, sa valeur de sortie rťelle entre 0 et 1 et enfin l'erreur en rťtro-propagation.
Pour modťliser, on peut crťer un tableau de neurones tel que:
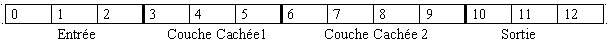
A chaque neurone du tableau on alloue un tableau de poids (w) correspondant aux connexions partants du neurone vers tous les neurones de la couche suivante.
Pour crťer un rťseau de n neurones, on crťe simplement un tableau de n neurones. On s'arrange ensuite pour garder en mťmoire la position des couches dans ce tableau.
L'algorithme utilisť
Source du programme en C: Cliquez ici
RťsultatsSix bases de donnťes ont ťtť testťes en gťnťralisation sur apprentissage avec líalgorithme de rťtro-propagation du gradient.
| Lenses | Iris | Bupa | Vote | Mushroom | Chess |
|---|---|---|---|---|---|
|
24 cas |
150 cas |
345 cas |
435 cas |
8124 cas |
3196 cas |
|
5 entrťes |
8 entrťes |
22 entrťes |
16 entrťes |
55 entrťes |
37 entrťes |
|
3 sorties |
3 sorties |
2 sorties |
2 sorties |
2 sorties |
2 sorties |
La gťnťralisation sur apprentissage consiste ŗ reprťsenter au rťseau les donnťes qu'il a appris. Le rťsultat doit Ítre normalement de 0% d'erreur si le rťseau a effectivement bien appris.
Le premier tableau montre les rťsultats obtenus sur un rťseau mono-couche:

Le tableau suivant montre l'importance de bien choisir le nombre de couches dans son rťseau. En effet le raisonnement consistant ŗ dire que plus on met de couche plus le rťseau donnera de bons rťsultats est faux.
| Erreur | Lenses | Iris | Bupa | Vote | Mushroom | Chess |
|---|---|---|---|---|---|---|
|
0% |
. |
. |
22-5-2 |
16-5-2 |
55-5-2 |
37-5-2 |
|
. |
. |
22-4-2 |
16-3-2 |
55-2-2 |
. |
. |
|
0.09% |
. |
. |
. |
. |
37-2-2 |
. |
|
0.29% |
. |
. |
22-02 |
. |
. |
. |
|
2.67% |
. |
8-4-3 (75) |
. |
. |
. |
. |
|
4.17% |
5-3-3 |
. |
. |
. |
. |
. |
|
13% |
. |
8-4-3 (150) |
. |
. |
. |
. |
Erreur en fonction de l'architecture du rťseau en rťtro-propagation
 Retour
ŗ la page principale.
Retour
ŗ la page principale.